In the era of cloud-native applications, real-time analytics, and AI-driven workloads, traditional caching systems like Redis and Memcached are hitting their limits. Enter Microsoft Garnet—a next-generation open-source cache-store designed to deliver blazing speed, durability, and extensibility at scale. How It Started: From Research to Reality
Garnet was born out of Microsoft Research, where engineers spent nearly a decade reimagining the caching layer for modern infrastructure. The goal? Build a cache that could handle massive concurrency, tiered storage, and custom logic—without compromising performance.
Where Garnet Is Already Used in Azure
Garnet is not just a research project—it’s already in production use across several Microsoft services:
Azure Resource Graph: Powers fast, scalable queries across Azure resources.
Windows & Web Experiences Platform: Enhances responsiveness and data delivery for user-facing services.
These deployments validate Garnet’s readiness for enterprise-scale workloads.
Core Features of Garnet
Thread-scalable architecture: Efficient multi-threading within a single node.
Cluster-native design: Built-in sharding, replication, and failover.
Durability: Supports persistent storage via SSDs and cloud (Azure Storage).
ACID Transactions: Ensures consistency for complex operations.
Extensibility: Custom modules and APIs for tailored functionality.
RESP Protocol Support: Compatible with Redis clients.
Tiered Storage: Operates across RAM, SSD, and cloud seamlessly.
Low-latency performance: Designed for sub-millisecond response times.
Client Compatibility: Plug-and-Play with Redis Ecosystem
Garnet supports the Redis Serialization Protocol (RESP), making it compatible with most Redis clients:
StackExchange.Redis (C#)
redis-py (Python)
node-redis (Node.js)
Jedis (Java)
This means team can switch to Garnet without rewriting client code.
Architecture Overview
Garnet’s architecture is built around:
Single-node thread-scalable execution
Clustered sharded execution
Log-structured memory and storage
Custom command registration and module APIs
This modular design allows Garnet to scale horizontally while remaining highly customizable.
Use Cases
Real-time web applications
Gaming backends
AI inference caching
IoT telemetry buffering
Cloud-native microservices
What Makes Garnet Different?
Performance Benchmarks Garnet has demonstrated:
2x throughput compared to Redis in multi-threaded scenarios
Lower tail latency under high concurrency
Efficient memory usage with log-structured storage
Future Roadmap
Microsoft plans to:
Deepen Azure integration
Expand module ecosystem
Enhance observability and telemetry
Support more advanced data types and indexing
Garnet is open-source and available on GitHub. we can run it locally, in containers, or integrate it into your cloud stack.
Getting Started
git clone https://github.com/microsoft/garnet cd garnet dotnet run
Final Thoughts
Microsoft Garnet isn’t just another cache—it’s a platform for building intelligent, scalable, and durable data services. Whether you’re optimizing latency for a web app or building a distributed AI pipeline, Garnet offers the flexibility and performance to meet your needs.
In a world where milliseconds matter, the performance of your in-memory cache can make or break user experience. Enter Microsoft Garnet, the next-generation cache-store that’s quietly—but powerfully—changing the game in distributed application performance.
🚀 What Is Microsoft Garnet?
Developed by Microsoft Research, Garnet is a high-throughput, low-latency, open-source remote cache that’s compatible with Redis clients. It speaks the RESP protocol, supports cluster sharding, replication, and checkpointing, and is written entirely in modern C#. Designed for scale, Garnet is now used internally by services like:
🔷 Azure Resource Manager
🔷 Azure Resource Graph
🔷 Windows and Web Experiences Platform
In short: this isn’t a toy project. It’s production-ready—because it’s already powering some of Microsoft’s most demanding services.
⚙️ Key Features
Feature
What It Means
✅ Redis Protocol Support
Drop-in replacement for many Redis workloads
📦 Cluster Sharding
Distributes cache across nodes for scale
🔁 Replication & Recovery
Ensures resilience and data safety
⚡ Native C# Implementation
.NET-optimized and developer-friendly
📋 Checkpointing
Built-in persistence for restarts and crashes
🛠️ Getting Started in Minutes
You can be up and running locally in just a few steps:
bash
git clone https://github.com/microsoft/garnet.git
cd garnet/src/GarnetServer
dotnet build -c Release
dotnet run
Want Docker?
bash
docker pull mcr.microsoft.com/garnet
docker run -p 3278:3278 mcr.microsoft.com/garnet
Garnet listens on port 3278 by default and supports many standard Redis commands like SET, GET, INCR, DEL, and more.
🧪 IS garnet Production-Ready?
Garnet is now in production inside Microsoft and is being actively maintained. If you’re building systems that demand ultra-low latency with .NET-friendly tooling—or you’re tired of paying for cloud Redis instances—Garnet might just be your hero.
Just keep in mind:
It’s ideal for read-heavy, ephemeral caching scenarios
It’s still rapidly evolving—watch the GitHub repo for updates
📚 Learn More
🧠 Official Garnet Docs
🔬 Microsoft Research: Garnet
💻 GitHub Repository
Final thoughts:
Garnet isn’t trying to be Redis. It’s trying to be something leaner, faster, and .NET-native—with the kind of performance that’ll give your data layer superpowers. Don’t just follow the trend—start caching like it’s 2025.
Jira Data Center is a powerful tool for managing enterprise-scale workflows, but even the best platforms encounter bugs. If you’re running Jira Data Center 10.3.3, you may have noticed inconsistent behavior with asynchronous webhooks, leading to incorrect payloads, delivery delays, and increased database strain. Atlassian has documented this issue, with fixes available in later versions. In this blog, we’ll explore the details of the problem and how to resolve it.
Understanding the Webhook Issue
Webhooks are crucial for real-time data synchronization between Jira and external applications. However, in Jira 10.3.3, asynchronous webhooks suffer from a request cache mismanagement issue, leading to:
Inconsistent payload data – Webhooks may send outdated or incorrect information.
Webhook failures – If queue limits are exceeded, webhooks may be dropped entirely.
Users may observe errors similar to this in their logs:
Invalid use of RequestCache by thread: webhook-dispatcher
This issue arises because asynchronous webhooks fail to properly retain the correct request cache instance, causing a disconnect between webhook events and actual data retrieval.
Temporary Workarounds for Jira 10.3.3
If upgrading is not immediately possible, consider these interim solutions:
Use Synchronous Webhooks
Synchronous webhooks do not rely on the flawed caching mechanism.
If your integration allows, temporarily switch critical webhooks to synchronous execution.
Reduce Webhook Frequency
Limit unnecessary webhook triggers to reduce queue congestion.
Adjust webhook filters to only trigger on essential events.
Monitor and Retry Failed Webhooks
Implement manual webhook retries by tracking failed webhook logs.
Use automation tools like scripts or API calls to resend failed events.
Optimize Queue Limits
Modify atlassian-jira.properties to adjust webhook dispatch settings.
Increasing queue size slightly may help mitigate dropouts.
These workarounds can help stabilize webhook behavior while waiting for a long-term fix.
Upgrade Tips: Moving to a Fixed Version
Atlassian has resolved this issue in Jira Data Center 10.3.6, 10.6.1, and 10.7.0. If possible, upgrading to one of these versions is the recommended solution.
Steps for a Smooth Upgrade
Backup Your Data – Always take a full database backup before upgrading.
Review Plugin Compatibility – Some third-party plugins may require updates.
Test in a Staging Environment – Run the upgrade in a test instance before deploying in production.
Monitor Post-Upgrade Webhook Performance – Verify that webhooks behave correctly after the update.
Upgrading to a fixed version not only resolves the webhook problem but can also improve Jira’s overall performance and stability.
Final Thoughts
Webhooks are essential for integrating Jira with external tools, automating workflows, and maintaining data consistency. If you’re facing issues with asynchronous webhooks in Jira Data Center 10.3.3, upgrading to a patched version is the best approach. If immediate upgrading isn’t feasible, the temporary workarounds discussed above can help mitigate disruptions.
Have you encountered this issue? Share your experiences and solutions in the comments!
Mastering Slack Workspaces: Building Collaborative Excellence
Slack isn’t just another tool in the digital workspace arsenal. It’s a meticulously designed ecosystem where teams come together to create, collaborate, and innovate. Let’s dive into the fundamentals of setting up workspaces, uncovering the blueprint for Enterprise Grid, and understanding the art of managing workspace visibility and access.
What Is a Slack Workspace?
In Slack’s world, a workspace is the central hub of your team’s activities. It’s not just a collection of conversations—it’s a dynamic environment tailored for collaboration. While a workspace is your command center, channels within it act as specialized neighborhoods for focused discussions.
Setting Up Your Workspace: A Step-by-Step Guide
Creating your workspace is straightforward yet impactful:
Start with the Basics Visit slack.com/create and follow the prompts to set up your space. Select a name reflecting your company’s identity and ensure the workspace URL aligns with your brand.
Onboard Your Team Send email invitations or share invite links to make onboarding seamless.
Design Channels Intentionally Create topic-specific channels, such as #marketing or #help-desk, to streamline discussions.
Enhance Productivity with Apps Add tools and integrations that complement your workflows.
Designing the Ultimate Workspace
A well-designed workspace isn’t just functional—it fosters engagement:
Map Operations Reflect your organization’s structure by creating channels corresponding to departments or projects.
Define Roles and Permissions Clearly set who can create channels or invite members through settings.
Name Channels Strategically Use naming conventions to maintain clarity and relevance.
Conduct Regular Reviews Periodically assess your workspace to keep it aligned with evolving needs.
Embrace Feedback Adapt your design based on team input to ensure optimal functionality.
Enterprise Grid: The Blueprint for Large Organizations
For sprawling organizations, Slack’s Enterprise Grid acts as the motherboard, seamlessly connecting multiple workspaces. Imagine your company as a bustling city. Each department or project is a neighborhood, while the Enterprise Grid is the city plan that ties everything together.
Start with a Blueprint Sketch out your workspace plan using tools like Lucidchart and gather input from department heads to ensure alignment with team needs.
Plan for Growth Create fewer workspaces initially and expand as needed. Design templates with standardized settings, naming conventions, and permissions.
Balance Structure and Flexibility Clearly outline workspace purposes, and assign admins to oversee day-to-day operations.
Best Practices for Enterprise Grid
Avoid workspace sprawl; aim for the Goldilocks zone of just the right number of workspaces.
Use multi-workspace channels for broad collaborations.
Ensure every member has a “home” workspace and intuitive navigation.
Managing Visibility and Access: Be the Gatekeeper
Slack offers four visibility settings tailored to varying collaboration needs:
Open: Accessible to all in the organization.
By Request: Members apply for access, ensuring a moderated environment.
Invite-Only: Exclusive for invited members—ideal for confidential projects.
Hidden: Completely private and by invitation only.
Use tools like Slack Connect for secure external collaborations and manage permissions to maintain confidentiality where necessary.
The Power of Multi-Workspace Channels
Think of multi-workspace channels as the hallways connecting the various rooms in your city. They enable cross-department collaboration, such as creating a #product-launch channel for marketing and product teams to unite.
Set permissions thoughtfully to balance collaboration with confidentiality. Restrict posting rights for announcement-focused channels to maintain clarity and focus.
The Intersection of Culture and Technology
Great workspaces are a reflection of the team culture they foster. While technology facilitates collaboration, it’s the people and their needs that drive its success. Design your workspace to serve both.
Optimizing Data Transfer with Amazon Database Migration Service (DMS)
In today’s dynamic digital landscape, businesses are continually seeking ways to optimize operations, reduce costs, and enhance agility. One of the most effective strategies to achieve these goals is by migrating data to the cloud. Amazon Database Migration Service (DMS) is an invaluable tool that simplifies the process of migrating databases to Amazon Web Services (AWS).
What is Amazon DMS?
Amazon DMS is a managed service that facilitates the migration of databases to AWS quickly and securely. It supports various database engines, including:
Amazon Aurora
PostgreSQL
MySQL
MariaDB
Oracle
SQL Server
SAP ASE
and more!
With Amazon DMS, businesses can migrate data while minimizing downtime, making it ideal for operations that require continuous availability.
Key Features of Amazon DMS
Ease of Use: Amazon DMS is designed to be user-friendly, allowing you to start a new migration with just a few clicks in the AWS Management Console.
Minimal Downtime: A key feature of Amazon DMS is its ability to keep the source database operational during the migration, ensuring minimal disruption to business activities.
Support for Heterogeneous Migrations: Amazon DMS supports both homogeneous (same database engine) and heterogeneous (different database engines) migrations, providing flexibility to switch to the most suitable database engine.
Continuous Data Replication: Amazon DMS enables continuous data replication from your source database to your target database, keeping them synchronized throughout the migration.
Reliability and Scalability: Leveraging AWS’s robust infrastructure, Amazon DMS provides high availability and scalability to handle your data workload demands.
Cost-Effective: With a pay-as-you-go pricing model, Amazon DMS offers a cost-effective solution, meaning you only pay for the resources used during the migration.
How Amazon DMS Works
Step 1: Setup the Source and Target Endpoints
The initial step in using Amazon DMS is to configure your source and target database endpoints. The source endpoint is the database you are migrating from, and the target endpoint is the database you are migrating to.
Step 2: Create a Replication Instance
Next, create a replication instance responsible for executing migration tasks and running the replication software.
Step 3: Configure Migration Tasks
Once the replication instance is set up, configure migration tasks that define the specific data to be migrated and the type of migration (full load, change data capture, or both).
Step 4: Start the Migration
With everything configured, start the migration process. Amazon DMS will migrate the data as specified in your migration tasks, ensuring minimal downtime and continuous data replication.
Step 5: Monitor and Optimize
Monitor the progress and performance of your tasks using the AWS Management Console. Amazon DMS provides detailed metrics and logs to help optimize the migration process.
Database Consolidation
Amazon DMS is perfect for database consolidation, simplifying the management and reducing costs by consolidating multiple databases into a single database engine. This process improves performance and optimizes resource utilization.
Benefits of Database Consolidation
Simplified Management: Managing a single database engine is easier than handling multiple disparate systems.
Cost Reduction: Consolidating databases can lead to significant cost savings by reducing licensing and maintenance expenses.
Improved Performance: A consolidated database environment can optimize resource utilization and enhance overall performance.
Schema Conversion Tool (SCT)
The Schema Conversion Tool (SCT) complements Amazon DMS by simplifying the migration of database schemas. SCT automatically converts source database schemas to formats compatible with target database engines, including database objects like tables, indexes, and views, as well as application code like stored procedures and functions.
Data Warehouse Support: SCT supports data warehouse conversions, allowing businesses to migrate large-scale analytical workloads to AWS.
Additional Database Services
AWS offers a variety of managed database services that complement Amazon DMS, providing a comprehensive suite of tools to meet diverse data needs.
Amazon DocumentDB
Amazon DocumentDB is a fully managed document database service designed for JSON-based workloads, compatible with MongoDB. It offers high availability, scalability, and security, making it ideal for modern applications.
Amazon Neptune
Amazon Neptune is a fully managed graph database service optimized for storing and querying highly connected data. It supports Property Graph and RDF models, making it suitable for social networking, recommendation engines, and fraud detection.
Amazon Quantum Ledger Database (QLDB)
Amazon QLDB is a fully managed ledger database providing a transparent, immutable, and cryptographically verifiable transaction log. It is perfect for applications requiring an authoritative transaction record, such as financial systems, supply chain management, and identity verification.
Managed Blockchain Database
AWS Managed Blockchain enables the creation and management of scalable blockchain networks, supporting frameworks like Hyperledger Fabric and Ethereum. It is ideal for building decentralized applications.
Amazon ElastiCache
Amazon ElastiCache is a fully managed in-memory data store and cache service supporting Redis and Memcached. It accelerates web application performance by reducing latency and increasing throughput, suitable for caching, session management, and real-time analytics.
Amazon DynamoDB Accelerator (DAX)
Amazon DynamoDB Accelerator (DAX) is a fully managed, in-memory cache for DynamoDB, providing fast read performance and reducing response times from milliseconds to microseconds. It is perfect for high read throughput and low-latency access use cases like gaming, media, and mobile applications.
Conclusion
Amazon Database Migration Service (DMS) is a versatile tool that simplifies database migration to the AWS cloud. Whether you’re consolidating databases, using the Schema Conversion Tool, or leveraging additional AWS database services like Amazon DocumentDB, Amazon Neptune, Amazon QLDB, Managed Blockchain, Amazon ElastiCache, or Amazon DAX, AWS offers a comprehensive suite of solutions to meet data needs.
Imagine a library where visitors can check out books at the front desk. After checking out their books, they enjoy reading them. However, suppose that a prankster checks out multiple books and never returns them. This causes the front desk to be unavailable to serve other visitors who genuinely want to check out books. The library can attempt to stop the false requests by identifying and blocking the prankster.
In this scenario, the prankster’s actions are similar to a denial-of-service (DoS) attack.
Denial-of-Service (DoS) Attacks
A denial-of-service (DoS) attack is a deliberate attempt to make a website or application unavailable to users. In a DoS attack, a single threat actor targets a website or application, flooding it with excessive network traffic until it becomes overloaded and unable to respond. This denies service to users who are trying to make legitimate requests.
Distributed Denial-of-Service (DDoS) Attacks
Now, suppose the prankster enlists the help of friends. Together, they check out multiple books and never return them, making it increasingly difficult for genuine visitors to check out books. These requests come from different sources, making it impossible for the library to block them all. This is similar to a distributed denial-of-service (DDoS) attack.
In a DDoS attack, multiple sources are used to start an attack that aims to make a website or application unavailable. This can come from a group of attackers or even a single attacker using multiple infected computers (bots) to send excessive traffic to a website or application.
Types of DDoS Attacks
DDoS attacks can be categorized based on the layer of the Open Systems Interconnection (OSI) model they target. The most common attacks occur at the Network (Layer 3), Transport (Layer 4), Presentation (Layer 6), and Application (Layer 7) layers. For example, SYN floods target Layer 4, while HTTP floods target Layer 7.
Slowloris Attack
One specific type of DDoS attack is the Slowloris attack. In a Slowloris attack, the attacker tries to keep many connections to the target web server open and hold them open as long as possible. It does this by sending partial requests, none of which are completed, thus tying up the server’s resources. This can eventually overwhelm the server, making it unable to respond to legitimate requests.
UDP Flood Attack
Another type of DDoS attack is the UDP flood attack. In a UDP flood attack, the attacker sends a large number of User Datagram Protocol (UDP) packets to random ports on a target server. The server, unable to find applications at those ports, responds with ICMP “Destination Unreachable” packets. This process consumes the server’s resources, eventually making it unable to handle legitimate requests.
AWS Shield: Your DDoS Protection Solution
To help minimize the effect of DoS and DDoS attacks on your applications, you can use AWS Shield. AWS Shield is a service that protects applications against DDoS attacks, offering two levels of protection: Standard and Advanced.
AWS Shield Standard: Automatically protects all AWS customers at no cost. It defends your AWS resources from the most common, frequently occurring types of DDoS attacks. As network traffic comes into your applications, AWS Shield Standard uses various analysis techniques to detect malicious traffic in real-time and automatically mitigates it.
AWS Shield Advanced: A paid service that provides detailed attack diagnostics and the ability to detect and mitigate sophisticated DDoS attacks. It also integrates with other services such as Amazon CloudFront, Amazon Route 53, and Elastic Load Balancing. Additionally, you can integrate AWS Shield with AWS WAF by writing custom rules to mitigate complex DDoS attacks.
Additional AWS Protection Services
AWS Web Application Firewall (WAF): Protects your applications from web-based attacks, such as SQL injection and cross-site scripting (XSS).
Amazon CloudFront and Amazon Route 53: These services offer built-in DDoS protection and can be used to distribute traffic across multiple locations, reducing the impact of an attack.
Best Practices for DDoS Protection
To enhance your DDoS protection, consider the following best practices:
Use AWS Shield: Enable AWS Shield Standard for basic protection and consider upgrading to AWS Shield Advanced for more comprehensive coverage.
Deploy AWS WAF: Use AWS WAF to protect your web applications from common web-based attacks.
Leverage CloudFront and Route 53: Use these services to distribute traffic and mitigate the impact of DDoS attacks.
Monitor and Respond: Regularly monitor your applications and network traffic for signs of DDoS attacks and respond quickly to mitigate any potential impact.
Conclusion
DDoS attacks are a serious threat to the availability and performance of your applications. By leveraging AWS Shield and other AWS services, you can protect your applications from these attacks and ensure they remain available and responsive to your users.
Effortlessly Migrating Databases with AWS Database Migration Service
Exploring various database options on AWS often raises the question: what about existing on-premises or cloud databases? Should we start from scratch, or does AWS offer a seamless migration solution? Enter Amazon Database Migration Service (DMS), designed to handle exactly that.
Amazon Database Migration Service (DMS)
Amazon DMS allows us to migrate our existing databases to AWS securely and efficiently. During the migration process, our source database remains fully operational, ensuring minimal downtime for dependent applications. Plus, the source and target databases don’t have to be of the same type.
Homogeneous Migrations
Homogeneous migrations involve migrating databases of the same type, such as:
MySQL to Amazon RDS for MySQL
Microsoft SQL Server to Amazon RDS for SQL Server
Oracle to Amazon RDS for Oracle
The compatibility of schema structures, data types, and database code between the source and target simplifies the process.
Heterogeneous Migrations
Heterogeneous migrations deal with databases of different types and require a two-step approach:
Schema Conversion: The AWS Schema Conversion Tool converts the source schema and code to match the target database.
Data Migration: DMS then migrates the data from the source to the target database.
Beyond Simple Migrations
AWS DMS isn’t just for migrations; it’s versatile enough for a variety of scenarios:
Development and Test Migrations: Migrate a copy of our production database to development or test environments without impacting production users.
Database Consolidation: Combine multiple databases into one central database.
Continuous Replication: Perform continuous data replication for disaster recovery or geographic distribution.
Additional AWS Database Services
AWS provides a suite of additional database services to meet diverse data management needs:
Amazon DocumentDB: A document database service that supports MongoDB workloads.
Amazon Neptune: A graph database service ideal for applications involving highly connected datasets like recommendation engines and fraud detection.
Amazon Quantum Ledger Database (Amazon QLDB): A ledger database service that maintains an immutable and verifiable record of all changes to our data.
Amazon Managed Blockchain: A service for creating and managing blockchain networks with open-source frameworks, facilitating decentralized transactions and data sharing.
Amazon ElastiCache: Adds caching layers to our databases, enhancing the read times of common requests. Supports Redis and Memcached.
Amazon DynamoDB Accelerator (DAX): An in-memory cache for DynamoDB that improves response times to microseconds.
Wrap-Up
Whether we’re migrating databases of the same or different types, AWS Database Migration Service (DMS) provides a robust and flexible solution to ensure smooth, secure migrations with minimal downtime. Additionally, AWS’s range of database services offers solutions for various other data management needs.
For further details, be sure to visit the AWS Database Migration Service page.
AWS offers a variety of powerful analytics services designed to handle different data processing needs. In this blog, we will focus on Amazon Athena, Amazon EMR, AWS Glue, and Amazon Kinesis, as these services are most likely to appear on the AWS Certified Cloud Practitioner exam. You can follow the links provided to learn more about other AWS analytics services like Amazon CloudSearch, Amazon OpenSearch Service, Amazon QuickSight, Amazon Data Pipeline, AWS Lake Formation, and Amazon MSK.
Amazon Elastic MapReduce (EMR)
Amazon EMR is a web service that allows businesses, researchers, data analysts, and developers to process vast amounts of data efficiently and cost-effectively. EMR uses a hosted Hadoop framework running on Amazon EC2 and Amazon S3 and supports Apache Spark, HBase, Presto, and Flink. Common use cases include log analysis, financial analysis, and ETL activities.
A Step is a programmatic task that processes data, while a cluster is a collection of EC2 instances provisioned by EMR to run these Steps. EMR uses Apache Hadoop, an open-source Java software framework, as its distributed data processing engine.
EMR is an excellent platform for deploying Apache Spark, an open-source distributed processing framework for big data workloads that utilizes in-memory caching and optimized query execution. You can also launch Presto clusters, an open-source distributed SQL query engine designed for fast analytic queries against large datasets. All nodes for a given cluster are launched in the same Amazon EC2 Availability Zone.
You can access Amazon EMR through the AWS Management Console, Command Line Tools, SDKs, or the EMR API. With EMR, you have access to the underlying operating system and can SSH in.
Amazon Athena
Amazon Athena is an interactive query service that allows you to analyze data in Amazon S3 using standard SQL. As a serverless service, there is no infrastructure to manage, and you only pay for the queries you run. Athena is easy to use: simply point to your data in Amazon S3, define the schema, and start querying using standard SQL.
Athena uses Presto with full standard SQL support and works with various data formats, including CSV, JSON, ORC, Apache Parquet, and Avro. It is ideal for quick ad-hoc querying and integrates with Amazon QuickSight for easy visualization. Athena can handle complex analysis, including large joins, window functions, and arrays, and uses a managed Data Catalog to store information and schemas about the databases and tables you create for your data stored in Amazon S3.
AWS Glue
AWS Glue is a fully managed, pay-as-you-go, extract, transform, and load (ETL) service that automates data preparation for analytics. AWS Glue automatically discovers and profiles data via the Glue Data Catalog, recommends and generates ETL code to transform your source data into target schemas, and runs the ETL jobs on a fully managed, scale-out Apache Spark environment to load your data into its destination.
AWS Glue allows you to set up, orchestrate, and monitor complex data flows, and you can create and run an ETL job with a few clicks in the AWS Management Console. Glue can discover both structured and semi-structured data stored in data lakes on Amazon S3, data warehouses in Amazon Redshift, and various databases running on AWS. It provides a unified view of data via the Glue Data Catalog, which is available for ETL, querying, and reporting using services like Amazon Athena, Amazon EMR, and Amazon Redshift Spectrum. Glue generates Scala or Python code for ETL jobs that you can customize further using familiar tools. As a serverless service, there are no compute resources to configure and manage.
Data Analysis and Query Use Cases
AWS offers several query services and data processing frameworks to address different needs and use cases, such as Amazon Athena, Amazon Redshift, and Amazon EMR.
Amazon Redshift provides the fastest query performance for enterprise reporting and business intelligence workloads, especially those involving complex SQL with multiple joins and sub-queries.
Amazon EMR simplifies and makes it cost-effective to run highly distributed processing frameworks like Hadoop, Spark, and Presto, compared to on-premises deployments. It is flexible, allowing you to run custom applications and code and define specific compute, memory, storage, and application parameters to optimize your analytic requirements.
Amazon Athena offers the easiest way to run ad-hoc queries for data in S3 without needing to set up or manage any servers.
Below is a summary of primary use cases for a few AWS query and analytics services:
AWS Service
Primary Use Case
When to Use
Amazon Athena
Query
Run interactive queries against data directly in Amazon S3 without worrying about data formatting or infrastructure management. Can be used with other services such as Amazon Redshift.
Amazon Redshift
Data Warehouse
Pull data from multiple sources, format and organize it, store it, and support complex, high-speed queries for business reports.
Amazon EMR
Data Processing
Highly distributed processing frameworks like Hadoop, Spark, and Presto. Run scale-out data processing tasks for applications such as machine learning, graph analytics, data transformation, and streaming data.
AWS Glue
ETL Service
Transform and move data to various destinations. Used to prepare and load data for analytics. Data sources can be S3, Redshift, or other databases. Glue Data Catalog can be queried by Athena, EMR, and Redshift Spectrum.
Amazon Kinesis
Amazon Kinesis makes it easy to collect, process, and analyze real-time, streaming data for timely insights and quick reactions to new information. It offers a collection of services for processing streams of various data, processed in “shards.” There are four types of Kinesis services:
Kinesis Video Streams
Kinesis Video Streams securely streams video from connected devices to AWS for analytics, machine learning (ML), and other processing. It durably stores, encrypts, and indexes video data streams, allowing access to data through easy-to-use APIs. Data producers provide data streams, stored for 24 hours by default, up to 7 days. Consumers receive and process data, with multiple shards in a stream and support for server-side encryption (KMS) with a customer master key.
Kinesis Data Streams
Kinesis Data Streams enables custom applications that process or analyze streaming data for specialized needs. It allows real-time processing of streaming big data, rapidly moving data off data producers and continuously processing it. Kinesis Data Streams stores data for later processing by applications, differing from Firehose, which delivers data directly to AWS services.
Common use cases include:
Accelerated log and data feed intake
Real-time metrics and reporting
Real-time data analytics
Complex stream processing
Kinesis Data Firehose
Kinesis Data Firehose is the easiest way to load streaming data into data stores and analytics tools. It captures, transforms, and loads streaming data, enabling near real-time analytics with existing business intelligence tools and dashboards. Firehose can use Kinesis Data Streams as sources, batch, compress, and encrypt data before loading, and synchronously replicate data across three availability zones (AZs) as it is transported to destinations. Each delivery stream stores data records for up to 24 hours.
Kinesis Data Analytics
Kinesis Data Analytics is the easiest way to process and analyze real-time, streaming data using standard SQL queries. It provides real-time analysis with use cases including:
Generating time-series analytics
Feeding real-time dashboards
Creating real-time alerts and notifications
Quickly authoring and running powerful SQL code against streaming sources
Kinesis Data Analytics can ingest data from Kinesis Streams and Firehose, outputting to S3, Redshift, Elasticsearch, and Kinesis Data Streams.
Deploying an Application Using Elastic Beanstalk: A Step-by-Step Guide
We can see here deploying a basic PHP based application using AWS beanstalk service. we want to run y our application in AWS without having to provision, configure, or manage the EC2 instances ourself.
Creating a Service Role for Elastic Beanstalk
First, you’ll need to create a service role for Elastic Beanstalk, allowing the service to deploy AWS services on your behalf. Follow these steps:
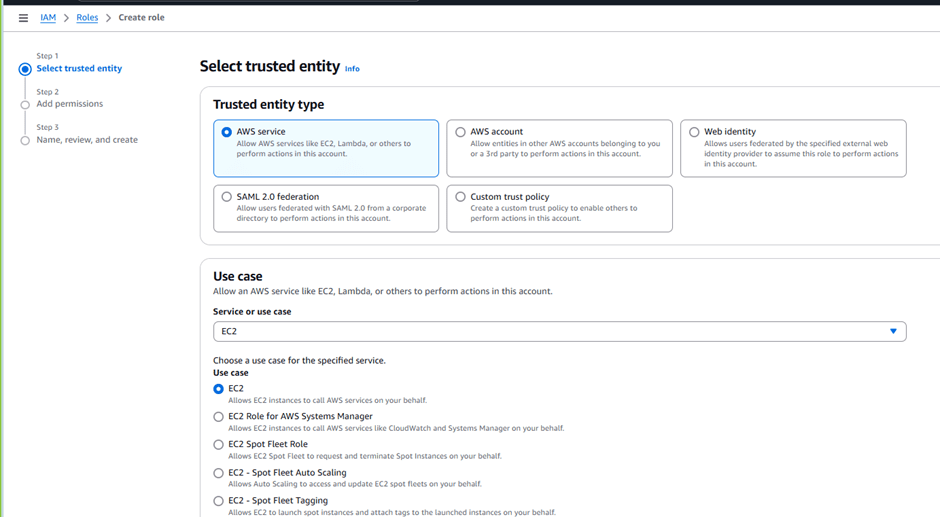
Search for IAM in the AWS console.
Select “Roles” and then “Create role”.
Set the Trusted entity type to AWS service.
Under Use cases, search for Elastic Beanstalk and select “Elastic Beanstalk – Customizable”.
Click “Next”, and then “Next” again as the permissions are automatically selected.
Name the role ServiceRoleForElasticBeanstalk.
Scroll to the bottom and click “Create role”.
REFERENCE SCREENSHOT
Configuring an EC2 Instance Profile for Elastic Beanstalk
Next, you’ll configure an EC2 instance profile to give the instance the required permissions to interact with Elastic Beanstalk:
Select “Create role” again in IAM.
Set the Trusted entity type to AWS service.
Under Use case, select EC2 under Commonly used services.
Click “Next”.
Search for AWS Elastic Beanstalk read only policy and select it.
Click “Next”.
Name the role CustomEC2InstanceProfileForElasticBeanstalk.
Scroll to the bottom and click “Create role”.
REFERENCE SCREENSHOT
Creating Your Application
Now, you’re ready to create your application by uploading the provided code:
Search for Elastic Beanstalk in the AWS console.
Select “Create application”.
Choose “Web server environment”.
Enter the application name as BeanStalkDemo.
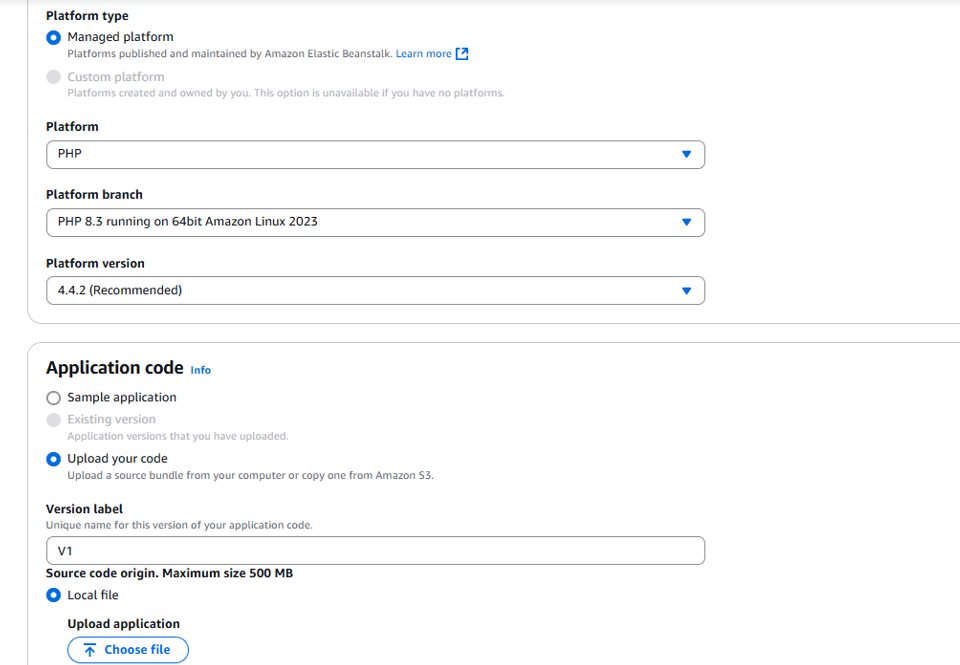
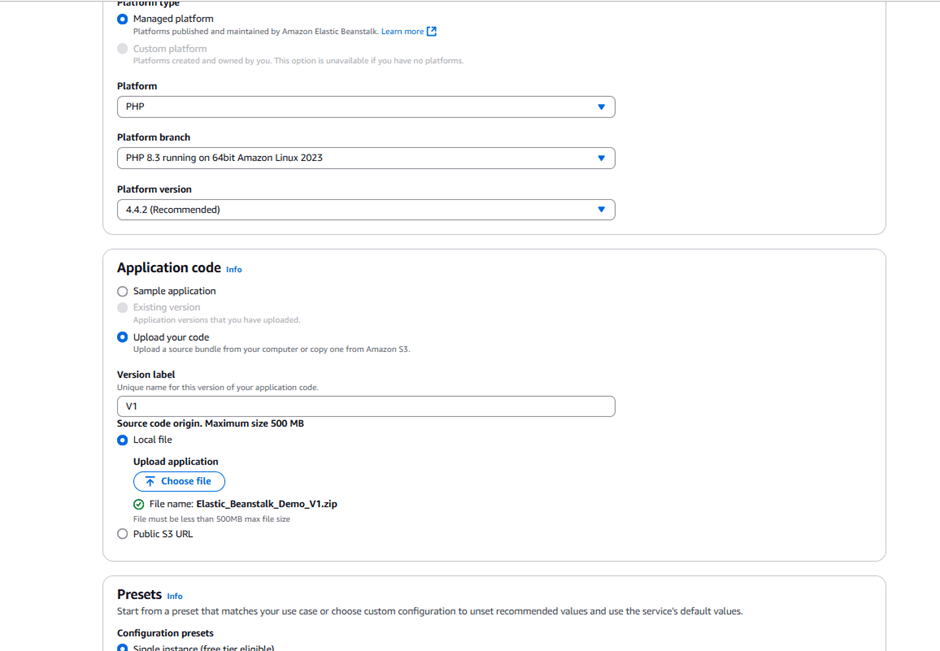
Choose a managed platform and select PHP.
Under Application code, upload your code. Set the version label to v1.
Use the file you downloaded earlier.
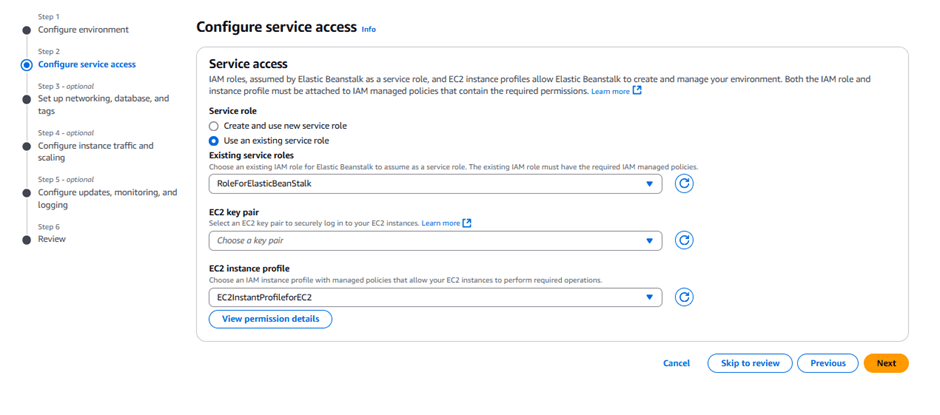
Under Service role, select ServiceRoleForElasticBeanstalk.
Under EC2 instance profile, select EC2InstanceProfileForElasticBeanstalk.
Click “Next” through the optional configuration pages.
On the Configure updates, monitoring, and logging page, select basic health reporting and deactivate managed updates.
Click “Submit”.
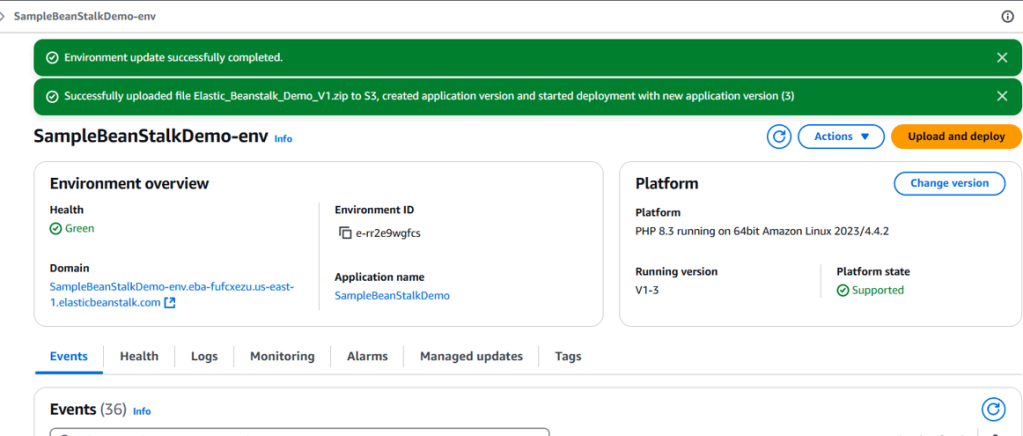
Launching and Accessing Your Application
After a few minutes, your Elastic Beanstalk environment will be ready. You’ll see a confirmation message, and you can click the domain URL under the Environment overview to access your application.
Hit the Domain URL it should take us to the deployed website.
And there you have it! Elastic Beanstalk deploys and scales your web applications, provisioning the necessary AWS resources such as EC2 instances, RDS databases, S3 storage, Elastic Load Balancers, and auto-scaling groups.